The problem
A leader in oil and gas exploration and production needed a holistic view of their data assets to perform analysis and make timely, effective business decisions. Terabytes of disparate data stored in 20 different systems hampered these efforts. The existing data estate was fragmented mainly due to an organizational philosophy that valued purchasing off-the-shelf software packages to handle specific types of data, leaving them unable to effectively collect, aggregate, analyze and report on data across their various systems.
“The company, like many others, hit critical mass when it came to their data. They had all these source systems and were asking more questions of the data,” said Blueprint Software Development Manager Anthony Sofio. “As they acquired more and more data, people had to spend more time gathering data than processing it. Soon the process became a nightmare of spreadsheets, databases and text files.”
The company was operating in a manually driven environment with little automated data ingestion and was using an antiquated OLAP reporting cube to analyze data. IP addresses had to be manually looked up and pinged to obtain micro-level completion and production data, and some data had never even been captured because of a lack of time and resources. Going further, the company wanted to be able to consume real-time pressure and temperature data from their tanks and pipelines and stream that data for analysis and predictive modeling.
The Blueprint Way
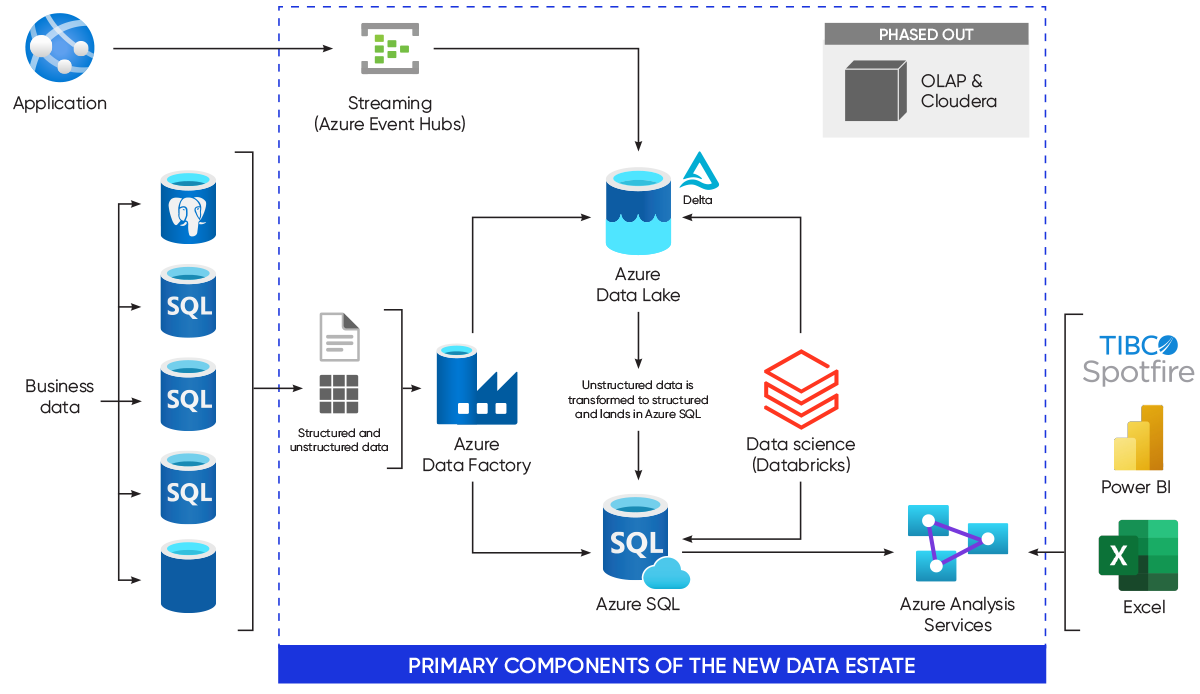
The initial goals of the company were to transition away from the antiquated OLAP cube and to finish decommissioning its dated, expensive Cloudera software platform. Blueprint approached the project in phases. The first phase involved setting up a technical foundation and beginning to migrate all existing data to an Azure Data Lake, where it was processed and transformed using Azure Databricks before being fed into a cloud data warehouse. Phase two established data pipelines for all data sources to allow ongoing data ingestion and scalability. It also included transitioning from the hard-to-maintain OLAP cube to a tabular data model as well as decommissioning the company’s remaining data in Cloudera, which reduced SaaS spend by $120,000 a year. With 21 data entities from seven sources consolidated into the company’s data estate, all data was consolidated under one analytical roof for the first time. This allows the company to monitor, audit and maintain all their data as well as bring in analytical tools, such as Power BI, to run analytics and reports for quick decision-making at a company level.
Combining the power of Azure event hubs, Azure Stream Analytics and Azure Time Series Insights, Blueprint also constructed a near real-time streaming data pipeline for production data, allowing the data to be queried and analyzed as it comes off the point of collection.
The final phase of this project is what Blueprint call “the art of the possible.” The nature of this solution provides the opportunity for data scientists to use advanced analytics and AI for predictive modeling in addition to allowing more general users to explore their data in a self-service BI scenario via tools like Power BI.
FROM THE CLIENT
“The modern data lake and platform that was built and provided by Blueprint is increasingly providing us value. Together, we have been able to successfully establish an enterprise warehouse in the cloud that contains data across most of our lines of business,” the company’s IT Technical Lead said. “In addition to the data, we have frameworks in place that allow us to leverage tools and techniques within the cloud ecosystem to tackle new analytical projects in a modern and mature way. As I look back on what was accomplished, I’m amazed with the amount of work that was delivered.”