The problem
The goal of this company is to provide law enforcement agencies with quick access to a wide universe of crime data to keep their communities safer. Law enforcement customers upload their data to the company’s vast database of crime information from other agencies around the country, broadening their search and analyses capabilities and allowing them to solve crimes in their jurisdiction more quickly.
Due to the company’s suboptimal data pipeline, however, it took between six and eight weeks to ingest a potential new customer’s data and demonstrate the capabilities of the platform. This threatened the company’s growth goals and its mission to unlock and distribute valuable crime data to solve and prevent crimes across the country.
The Blueprint Way
What used to take weeks to process takes only a few hours now... Our CEO will be dancing in the streets.
Senior Engineer, Product
The company initially reached out to Databricks to develop a proof of concept to rearchitect its data pipeline. Databricks completed an initial POC and partnered with Blueprint to demonstrate that a new data pipeline powered by Databricks would both reduce the time needed to onboard new clients and reduce compute costs for the company.
Blueprint identified a portion of the company’s architecture that depended on complex Java ETL and data enrichment tasks that were processed on expensive virtual machines. This piece of the pipeline was slowing down the onboarding process for new and potential clients significantly. By transitioning the company to a modern data ingestion pipeline with the Databricks Lakehouse at its core, Blueprint reduced the onboarding time from six to eight weeks to eight hours and saved the company hundreds of thousands per year.
(n+1)
While working on this project, Blueprint recognized a further challenge the company was facing with its data – one that impacted the searchability of crime reports. If a customer wanted to search for all thefts, crime reports would have to contain the word theft. This caused users to have to run multiple searches using different phrases – attempted burglary, breaking and entering, etc. Adding another layer of complexity was the fact that often, reports wouldn’t name the type of crime, but instead, they’d have the corresponding local code for the crime.
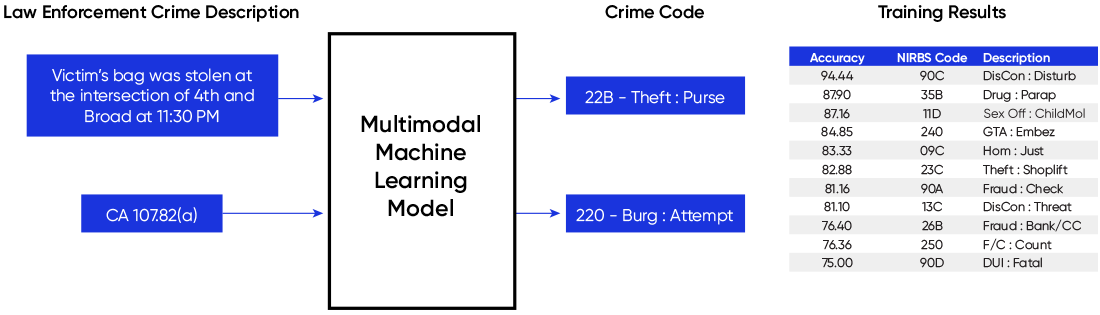
In just two weeks Blueprint delivered a machine learning model using an untapped source of data that increased search accuracy from 15% to 72%.
“The difference between a good data science team and someone who just copies code from Stack Overflow is where you go from there,” Blueprint’s Data Science Practice Lead said. “If you can Google ‘training a classification model,’ you can technically do this. But can you go from 15% to 72%? That’s where the data science comes in.”